Tệp robots.txt có một cấu trúc rất đơn giản. Có một số từ khóa/giá trị được xác định trước mà bạn có thể sử dụng. Phổ biến nhất là: User-agent, Disallow, Allow, Crawl-delay, Sitemap.
1. User-agent
Chỉ định trình thu thập dữ liệu nào được đưa vào các chỉ thị. Bạn có thể sử dụng một * để cho tất cả các trình thu thập thông tin hoặc nếu không thích thì bạn có thể chỉ định tên của trình thu thập thông tin, xem ví dụ dưới đây:
User-agent: * – bao gồm tất cả trình thu thập thông tin.
User-agent: Googlebot – chỉ dành cho Google bot.
2. Disallow
Chỉ thị hướng dẫn các bot (được chỉ định ở trên) không thu thập dữ liệu URL hoặc một phần của trang web.
Giá trị của disallow có thể là một tệp, URL hoặc thư mục cụ thể. Xem ví dụ dưới đây để hiểu rõ hơn:

3. Allow
Chỉ thị cho biết rõ các trang hoặc thư mục con nào có thể được truy cập. Điều này chỉ áp dụng cho Googlebot.
Bạn có thể sử dụng Allow để cho phép truy cập vào một thư mục con cụ thể trên trang web của bạn, mặc dù thư mục gốc là không được phép.
Ở ví dụ dưới đây, thư mục photo bị chặn nhưng lại được cho phép lập chỉ mục trong photos/vietnetgroup:
User-agent: *
Disallow: /photos
Allow: /photos/vietnetgroup/
4. Crawl-delay
Bạn có thể để cụ thể một giá trị để buộc trình thu thập dữ liệu thu thập thông tin của công cụ tìm kiếm phải đợi một khoảng thời gian cụ thể trước khi thu thập thông tin trang tiếp theo từ trang web của bạn. Giá trị bạn nhập đơn vị là mili giây.
Cần lưu ý rằng Googlebot không tính đến độ Crawl-delay này.
Bạn có thể sử dụng Google Search Console để kiểm soát tốc độ thu thập thông tin cho Google (tùy chọn này ở trong Cài đặt trang web) dưới đây: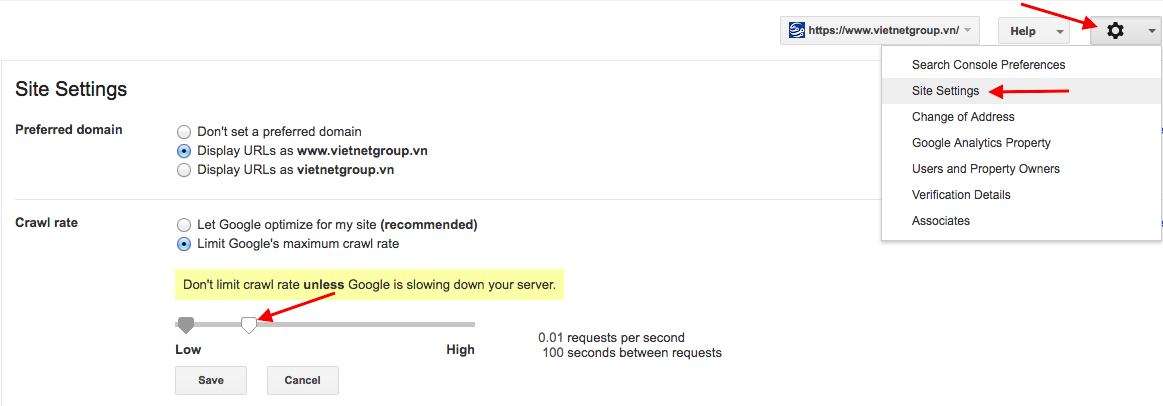
Bạn có thể sử dụng Crawl-delay trong trường hợp bạn có trang web với hàng ngàn trang và bạn không muốn quá tải máy chủ của mình với các yêu cầu liên tục.
Trong phần lớn các trường hợp, bạn không nên sử dụng chỉ thị thu thập dữ liệu trễ này.
5. Sitemap
Chỉ thị sitemap được hỗ trợ bởi các công cụ tìm kiếm chính bao gồm Google và nó được sử dụng để chỉ định vị trí của Sơ đồ trang web XML của bạn. Ngay cả khi bạn không chỉ định vị trí của sơ đồ trang XML trong robots.txt, các công cụ tìm kiếm vẫn có thể tìm thấy nó.
Một điều lưu ý quan trọng cho bạn đó là robots có phân biệt chữ hoa và chữ thường. Ví dụ: Disallow: /File.html thì sẽ không khóa được file.html.